Deepfakes是一種利用機器學習中的深度學習實現深度影片換臉的技術。而DeepFaceLab是眾多軟體中,安裝最簡單,使用最方便,更新最快的一款軟體。
安裝GPU模組
DeepFaceLab需要使用GPU,因此需安裝CUDA及cuDNN。
安裝CUDA:開啟https://developer.nvidia.com/cuda-toolkit-archive,點選CUDA Toolkit 10.1 update2。
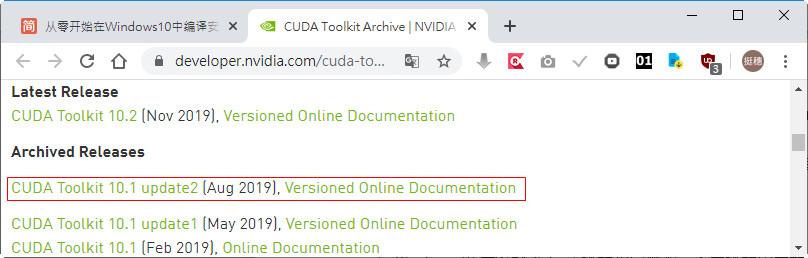
依照作業系統點選,此處點選「Windows、x86_64、10、exe(local)」,再按「Download」鈕下載。
下載完成後進行安裝(都使用預設值即可)。
安裝cuDNN:開啟https://developer.nvidia.com/cuDNN,點選「DOWNLOAD cuDNN」。下載cuDNN必須註冊為會員,註冊後登入,點選CUDA對應的版本,再點選作業系統 Windows 10下載。
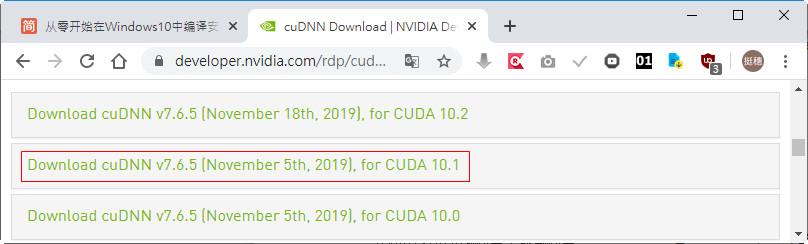
檔案下載後解壓縮,置於任意資料夾中,此處以<C:\Portable\cudnn-10.1-windows10-x64-v7.6.5.32>為例。然後將<C:\Portable\cudnn-10.1-windows10-x64-v7.6.5.32\cuda\bin>加入環境變數中。
安裝DeepFaceLab
開啟「https://github.com/iperov/DeepFaceLab」網頁,捲到下方「Release」處,點選「Windows (Mega.nz)」。

「Release」頁面有所有版本,最下方為最新版本,點選最下方右邊「功能」鈕,再點選「下載 / 下載為ZIP壓縮文檔」即可下載,檔案很大約3G,請耐心等待。

解壓縮下載的<Archive-bc1e.zip>檔得到<DeepFaceLab_NVIDIA_build_08_02_2020.exe>檔,雙按此執行檔就解壓縮得到<DeepFaceLab_NVIDIA>資料夾,內含影片變臉所有程式,其中已寫好許多批次檔,方便使用。

實作DeepFaceLab影片換臉
原始檔的<workspace>資料夾中有兩個影片檔可做為練習用:<data_src.mp4>及<data_dst.mp4>。
實作換臉的步驟為:(執行時若是許久沒反應,請按「ENTER」鍵)
執行<1) clear workspace.bat>:清除工作空間,重新進行影片換臉。

執行<2) extract images from video data_src.bat>:將原始影片轉換為圖片。
第一個輸入點:每秒擷取多少張圖片,建議10-30。
第二個輸入點:圖片格式,png或jpg。
執行完畢後會在<workspace\data_src>資料夾產生擷取圖片。

執行<3) extract images from video data_dst FULL FPS.bat>:將目標影片轉換為圖片。
第一個輸入點:圖片格式,png或jpg。(擷取的FPS為30)
執行完畢後會在<workspace\data_dst>資料產生擷取圖片。
執行<4) data_src faceset extract.bat>:從原始影片的圖片中擷取臉部圖形。
第一個輸入點:「CPU」表示使用CPU,「0」表示使用GPU。
第二個輸入點:「f」表示擷取臉部,「wf」表示完成臉部,「head」表示擷取頭部。
第三個輸入點:擷取圖片的最大數量,「0」表示無上限。
第四個輸入點:擷取圖片的尺寸,建議在512以下。
第五個輸入點:擷取圖片的品質,100為最高品質。
第六個輸入點:是否產生除錯圖片。
執行完畢後會在<workspace\data_src\aligned>資料夾產生臉部圖片。

執行<5) data_dst faceset extract.bat>:從目標影片的圖片中擷取臉部圖形。
第一個輸入點:「CPU」表示使用CPU,「0」表示使用GPU。
第二個輸入點:「f」表示擷取臉部,「wf」表示完成臉部,「head」表示擷取頭部。
第三個輸入點:擷取圖片的尺寸,建議在512以下。
第四個輸入點:擷取圖片的品質,100為最高品質。
執行完畢後會在<workspace\data_dst\aligned>資料夾產生臉部圖片,在<workspace\data_dst\aligned_debug>資料產生除錯圖片。
除錯圖片的臉部有一個紅色框和藍色框,還有一個綠色的輪廓線。如果發現綠色線和臉部輪廓不貼合,那麼就需要手動提取這張圖片了。必要時可以修正此圖片。

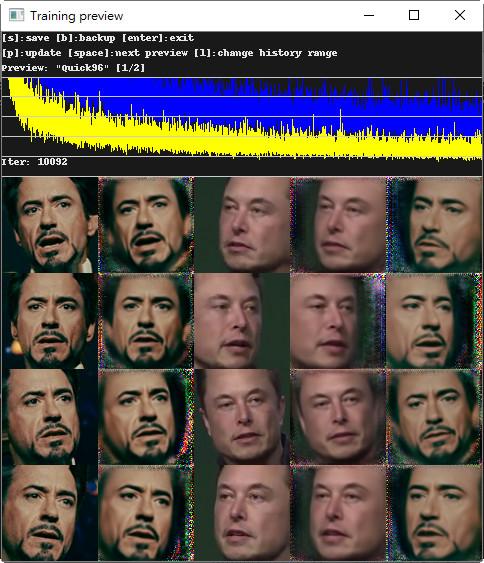
執行<6) train Quick96.bat>:快速訓練模型。(<6) train SAEHD.bat>可以自行定義許多訓練參數)
第一個輸入點:輸入模型名稱。
第二個輸入點:「CPU」表示使用CPU,「0」表示使用GPU。
開始訓練時,第二行及第四行圖片是模糊的,當此兩列圖片足夠清晰時,就可以按「ENTER」鍵完成訓練並儲存模型。訓練的時間依系統效能而定,可能數小時至數天。
執行完畢後會在<workspace\model>資料產生模型檔。
執行<7) merge Quick96.bat>:置換圖片。(選擇與訓練對應的程式)
第一個輸入點:「0」表示使用已存在的模型。
第二個輸入點:「CPU」表示使用CPU,「0」表示使用GPU。
第三個輸入點:是否使用互動模式,可輸入「n」。
第四個輸入點:合併模式,建議輸入「1」或「2」。
第五個輸入點:遮罩模式,建議輸入「1」。
後面皆為參數設定,建議都使用預設值,因此一宜按「ENTER」鍵即可。
執行完畢後會在<workspace\data_dst\merged>資料產生換臉後的圖片。
執行<8) merged to mp4.bat>:將圖片合成影片。
第一個輸入點:碼率,建議輸入「5」以下整數。數值越大,產生的檔案越大。
執行完畢後會在<workspace>資料產生<result.mp4>影片檔,這就是換臉後的影片。
沒有留言:
張貼留言